Nowe modele OpenAI o otwartym kodzie źródłowym mogą działać na Państwa komputerze

OpenAI ogłosiło wydanie gpt-oss-120b i gpt-oss-20b, dwóch modeli o otwartej wadze, które można pobrać bezpłatnie i uruchomić lokalnie w systemie. Jest to pierwsza wersja open-source firmy od czasu premiery GPT-2 w 2019 roku.
Gpt-oss-120b to model o 117 miliardach parametrów, który do działania wymaga 80 GB pamięci VRAM. Mniejszy gpt-oss-20b - model o 21 miliardach parametrów, może zmieścić się na pojedynczym GPU z 16 GB pamięci VRAM. Oba modele są dostępne na elastycznej licencji Apache 2.0.
OpenAI twierdzi, że "wydanie jest znaczącym krokiem w ich zaangażowaniu w ekosystem open source, zgodnie z ich deklarowaną misją, aby korzyści płynące ze sztucznej inteligencji były szeroko dostępne" Firma chce, aby służyły one jako tańsze narzędzie dla programistów, badaczy i firm do efektywnego uruchamiania i dostosowywania.
Jak się sprawdzają?
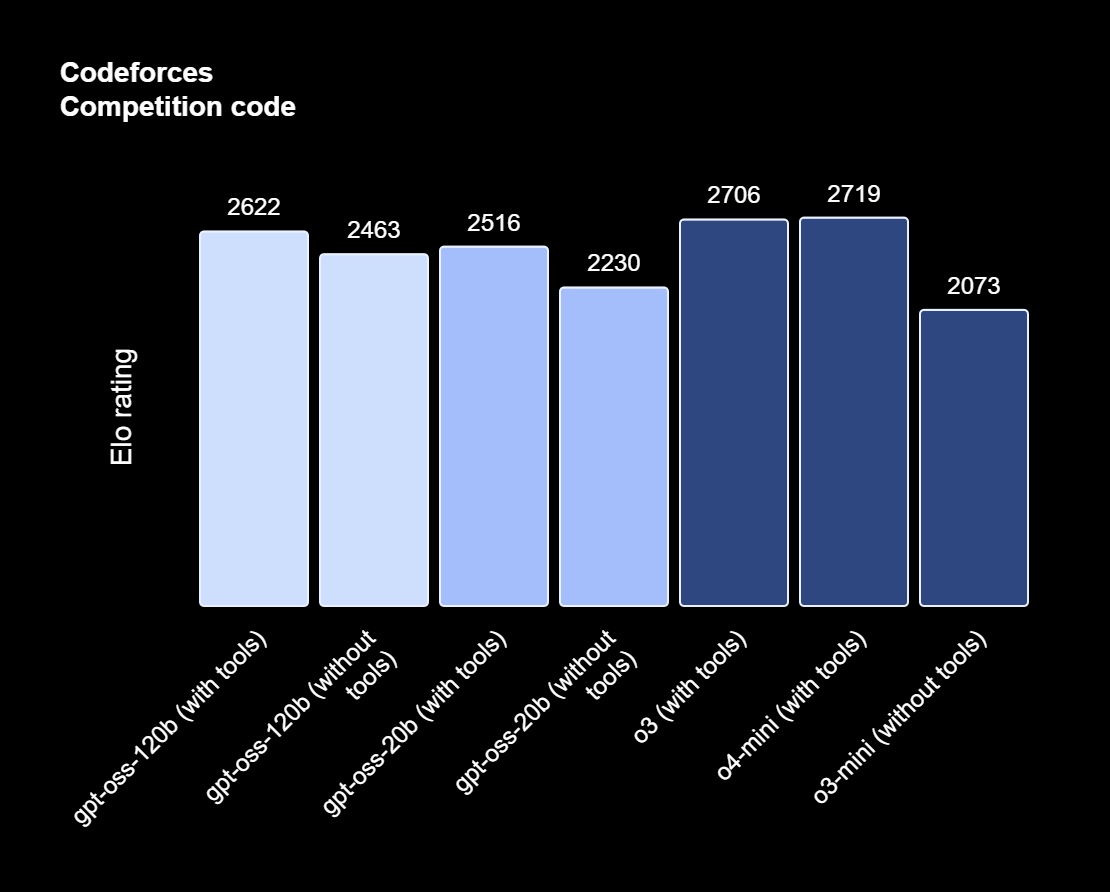
Model gpt-oss-120b uzyskał 2622 punkty w teście kodowania Codeforces z narzędziami, osiągając prawie takie same wyniki jak firmowe o3 i o4-mini, a także komfortowo pokonując o3-mini w obu testach, uzyskując 2643 punkty bez narzędzi.
Gpt-oss-20b uzyskał 2516 punktów z narzędziami, osiągając wyniki na równi z o3 i o4-mini z o3 i o4-mini oraz 2230 bez narzędzi, nieznacznie wyprzedzając o3-mini. OpenAI twierdzi, że 120b radzi sobie nawet lepiej z zapytaniami związanymi ze zdrowiem i matematyką niż o4-mini, podczas gdy 20b wyprzedza o3-mini.
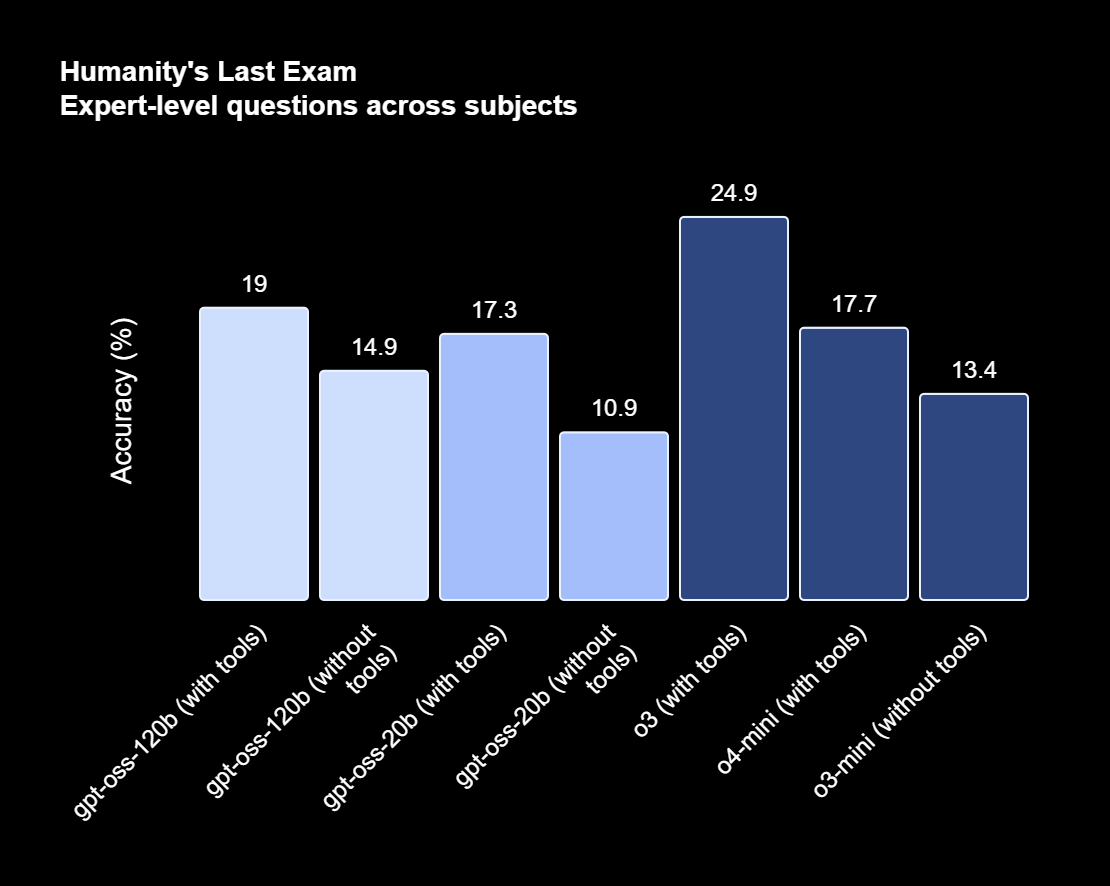
OpenAI twierdzi, że zarówno 120b, jak i 20b mają tendencję do halucynacji znacznie bardziej niż modele rozumowania, takie jak o3 i o4-mini. W testach okazało się, że oba modele open weight miały halucynacje w 49% do 53% w swoich wewnętrznych testach porównawczych, które testują modele pod kątem ich wiedzy o ludziach.
Oba modele można pobrać z oficjalnej strony Hugging Face space i są natywnie kwantyzowane w MXFP4 w celu zwiększenia wydajności. Można je również swobodnie wdrażać na platformach takich jak Microsoft Azure, Hugging Face, vLLM, Ollama i llama.cpp, LM Studio, AWS, Fireworks, Together AI i wiele innych.
OpenAI oczekuje, że modele te "obniżą bariery dla rynków wschodzących, sektorów o ograniczonych zasobach i mniejszych organizacji, którym może brakować budżetu lub elastyczności, aby przyjąć zastrzeżone modele"
Jeśli chodzi o powód udostępnienia nowego modelu sześć lat po ostatnim, firma twierdzi, że chce "uczynić sztuczną inteligencję szeroko dostępną i korzystną dla wszystkich"

