Najnowsze modele sztucznej inteligencji DeepSeek o otwartym kodzie źródłowym rzucają wyzwanie GPT-5 i Gemini 3.0 Pro

Po zdobyciu świat przez burzę i spowodowaniu tąpnięcia na amerykańskich giełdach w styczniu 2025 r., DeepSeek ogłosił teraz dwa nowe modele sztucznej inteligencji typu open source: DeepSeek V3.2 i DeepSeek V3.2-Speciale.
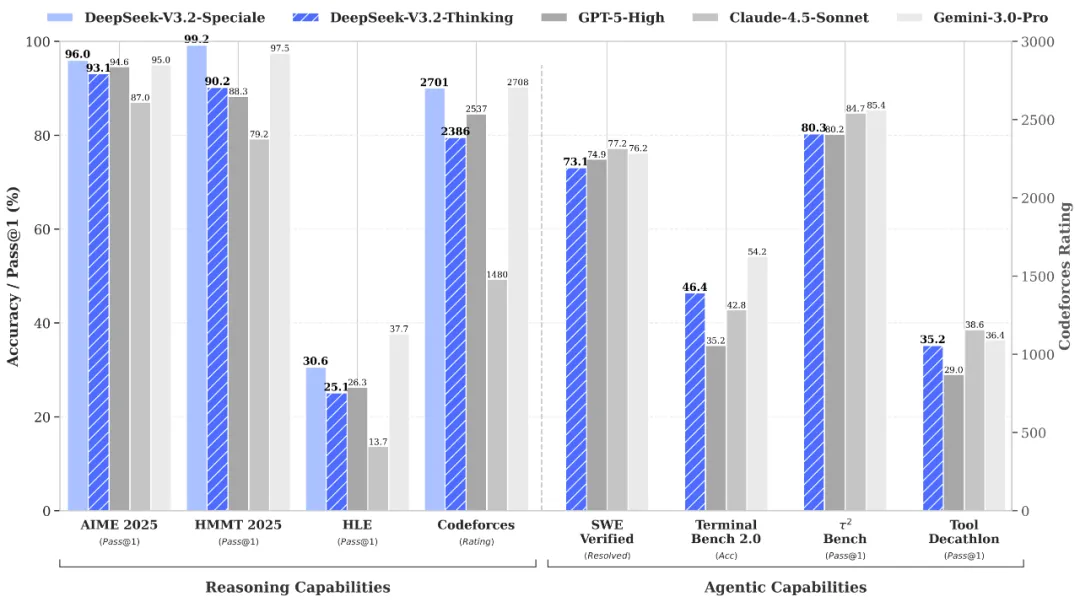
Wydanie to stanowi kontynuację wyraźnej strategii firmy w wyścigu zbrojeń AI. Podczas gdy OpenAI i Google zainwestowały miliardy dolarów w obliczenia, aby wytrenować swoje pionierskie modele, traktując priorytetowo wzrost wydajności za wszelką cenę, DeepSeek obrał inną ścieżkę. Jego poprzedni model R1 był godny uwagi, ponieważ udało mu się osiągnąć wydajność na równi z GPT 4o i Gemini 2.5 Pro dzięki sprytnym technikom wzmacniania, mimo że był trenowany na mniej zaawansowanych chipach.
Przewyższa GPT-5, jednocześnie dorównując Gemini 3 Pro Google
Standardowy DeepSeek-V3.2 jest pozycjonowany jako zrównoważony "codzienny kierowca", harmonizujący wydajność z wydajnością agentową, która według firmy jest porównywalna z GPT-5. Jest to również pierwszy model DeepSeek, który integruje myślenie bezpośrednio z używaniem narzędzi, przy czym to ostatnie jest dozwolone zarówno w trybie myślenia, jak i niemyślenia.
Jednak to wariant DeepSeek V3.2-Speciale o wysokiej wydajności obliczeniowej trafi na pierwsze strony gazet. DeepSeek twierdzi, że model Speciale przewyższa GPT-5 i rywalizuje z Gemini 3.0 Pro Google pod względem możliwości czystego rozumowania. Osiągnął nawet złoty medal w Międzynarodowej Olimpiadzie Matematycznej (IMO) 2025 i Międzynarodowej Olimpiadzie Informatycznej (IOI). Aby udowodnić, że nie jest to tylko marketingowy pucharek, DeepSeek twierdzi, że opublikował swoje ostateczne zgłoszenia do tych konkursów w celu weryfikacji przez społeczność.
DeepSeek przypisuje wzrost wydajności "DeepSeek Sparse Attention" (DSA), mechanizmowi zaprojektowanemu w celu zmniejszenia złożoności obliczeniowej w scenariuszach z długim kontekstem oraz skalowalnym ramom uczenia się ze wzmocnieniem.
Być może najbardziej interesujące dla deweloperów jest skupienie się na agentach. DeepSeek zbudował "potok syntezy zadań agentowych na dużą skalę", aby wytrenować model na ponad 85 000 złożonych instrukcji. Rezultatem jest model, który może zintegrować procesy "myślenia" bezpośrednio ze scenariuszami użycia narzędzi.
Dostępność
DeepSeek V3.2 jest już dostępny w sieci, aplikacjach mobilnych i API. Tymczasem wersja V3.2 Speciale jest obecnie dostępna tylko przez API i ma ściśle tymczasowy punkt końcowy, który wygasa 15 grudnia 2025 roku. Ponadto Speciale jest czystym silnikiem wnioskowania i nie obsługuje wywoływania narzędzi. Jeśli są Państwo zainteresowani uruchomieniem tych modeli lokalnie, firma udostępniła szczegółowe instrukcje dotyczące tego tutaj.