Zaskakujący język pokonuje angielski i chiński w testach LLM, w oparciu o nowe badanie akademickie

Nowe wielojęzyczne badanie, które ocenia, jak duże modele językowe radzą sobie z długimi dokumentami, przyniosło nieoczekiwane informacje: Język polski, a nie angielski czy chiński, wykazuje najwyższą dokładność, gdy okna kontekstowe rozciągają się do 64 000 tokenów i więcej. Wyniki pochodzą z testu porównawczego OneRuler przedstawionego w artykule COLM 2025w którym przetestowano 26 języków w zadaniach wyszukiwania i agregacji.
Badacze porównali dokładność modelu przy różnych długościach kontekstu i stwierdzili wyraźną zmianę, gdy sekwencje stały się dłuższe. Zgodnie z wykresem wyników (na stronie 6), język polski prowadzi we wszystkich językach ze średnią dokładnością 88% przy długich kontekstach. Angielski spada na szóste miejsce, a chiński plasuje się w dolnej czwórce.
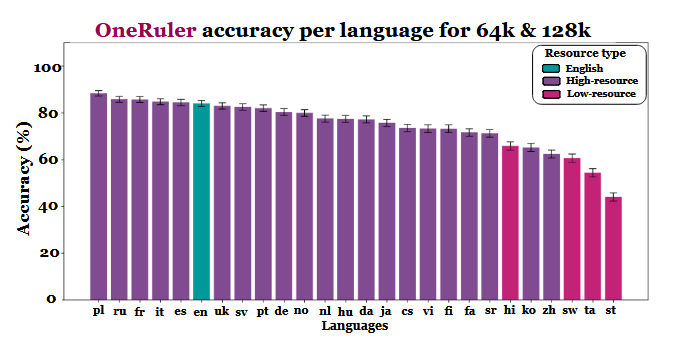
Badanie wskazuje, że rozbieżność może być związana z wydajnością tokenizacji i różnicami w skryptach, a nie tylko z ilością danych szkoleniowych. Języki używające alfabetu łacińskiego - takie jak polski, francuski i hiszpański - konsekwentnie osiągały lepsze wyniki niż te używające logograficznych lub abugidalnych systemów zapisu. Chiński, koreański, tamilski i inne wykazywały jedynie umiarkowaną dokładność nawet w krótszych kontekstach (a ich dokładność pogarszała się jeszcze bardziej, gdy sekwencje stawały się dłuższe). To całkowite odwrócenie oczekiwanych rankingów jest interesujące, ponieważ większość powszechnie stosowanych LLM jest szkolona głównie na zestawach danych w języku angielskim. Jednak wyniki artykułu wskazują, że gdy modele muszą wyszukiwać, przywoływać lub podsumowywać informacje zakopane głęboko w długich dokumentach, strukturalne aspekty języka biorą górę nad przewagą zbioru danych.
Inne wyniki benchmarku również potwierdzają tę interpretację. Różnica w wydajności między najsilniejszymi i najsłabszymi językami gwałtownie rośnie wraz z rozszerzaniem się kontekstu - od 11% przy 8 000 tokenów do 34% przy 128 000 tokenów. Inny szczegół badania pokazuje, jak wrażliwe mogą być te testy na niewielkie zmiany instrukcji. Na przykład, po prostu pozwalając modelowi odpowiedzieć "none", jeśli docelowy ciąg jest nieobecny, spowodował spadek dokładności w języku angielskim o 32% przy 128 tys. tokenów, jak widać na stronie 2.
Podczas gdy test porównawczy porównuje również rodziny modeli, wyniki sugerują, że ocena długiego kontekstu nie może opierać się wyłącznie na testach w języku angielskim i że uogólnienia wydajności w różnych językach mogą być mylące, jeśli zignoruje się efekty skryptu i tokenizacji. W miarę jak okna kontekstowe stają się coraz większe, różnice językowe stają się coraz ważniejsze, a nie mniej - a dominacja języka angielskiego w testach porównawczych LLM może nie być już reprezentatywna, gdy długość sekwencji wzrośnie do dziesiątek tysięcy.

Źródło(a)
Jedna miarka do mierzenia wszystkich: Benchmarking wielojęzycznych modeli językowych o długim kontekście na COLM 2025
Wyróżniony obraz autorstwa Zulfugar Karimov na Unsplash

