To poręczne narzędzie open source wyciąga dla mnie tekst ze wszystkiego - nawet z filmów i obrazów
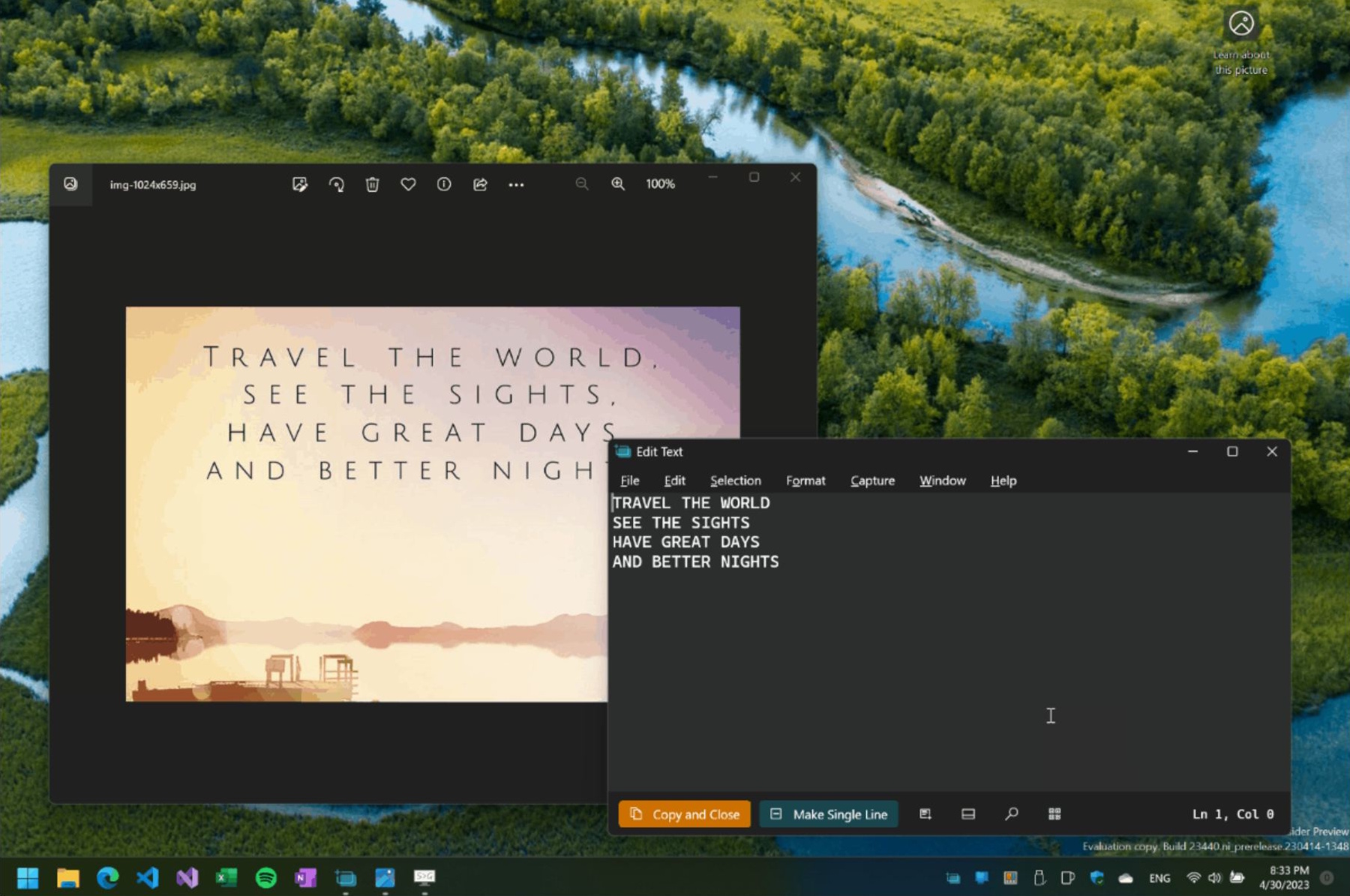
Czy znają Państwo ten problem? Większość plików PDF umożliwia bezproblemowe kopiowanie tekstu. Od czasu do czasu można jednak natknąć się na plik PDF, który najwyraźniej nie został utworzony z dokumentu tekstowego - został on wygenerowany na podstawie zeskanowanych obrazów, mimo że jego zawartość stanowi wyłącznie tekst. W takich przypadkach nie można niczego zaznaczyć ani skopiować, chyba że użyje się dodatkowych narzędzi. To frustrujące.
Inny przykład: Oglądam film o najlepszych gąsienicach RC (zdalnie sterowanych samochodach zbudowanych specjalnie do pokonywania ekstremalnie trudnego terenu) w określonym przedziale cenowym, ponieważ moje dziecko jest nimi zainteresowane. Nazwy modeli są pokazane w filmie, ale nigdzie nie można ich znaleźć jako tekstu do wyboru w opisie.

Tutaj z pomocą przychodzi Text Grab: To narzędzie open source jest dostępne na Github dla komputerów z systemem Windows x86 i ARM64 i robi dokładnie to, co chciałbym mieć w takich sytuacjach: wyodrębnia tekst z obrazów, filmów, plików PDF opartych na zdjęciach - w zasadzie ze wszystkiego, co pojawia się na ekranie.
Korzystanie z niej nie może być prostsze. Aplikacja działa jak standardowe narzędzie do zrzutów ekranu. Wystarczy zrobić zdjęcie całego ekranu lub tylko wybranego obszaru, a Text Grab natychmiast rozpozna tekst na obrazie i skopiuje go do schowka. Podobnie jak w przypadku innych narzędzi do zrzutów ekranu, można skonfigurować własne skróty klawiszowe do przechwytywania całego ekranu lub określonych regionów.
Pomimo tego, że aplikacja zajmuje tylko 74 MB, oferuje kilka sposobów przechwytywania tekstu. Można zeskanować cały ekran, narysować ramkę wokół mniejszego obszaru, a nawet kliknąć bezpośrednio pojedyncze słowo. W razie potrzeby narzędzie może automatycznie otworzyć Notatnik z wyodrębnionym tekstem gotowym do edycji.
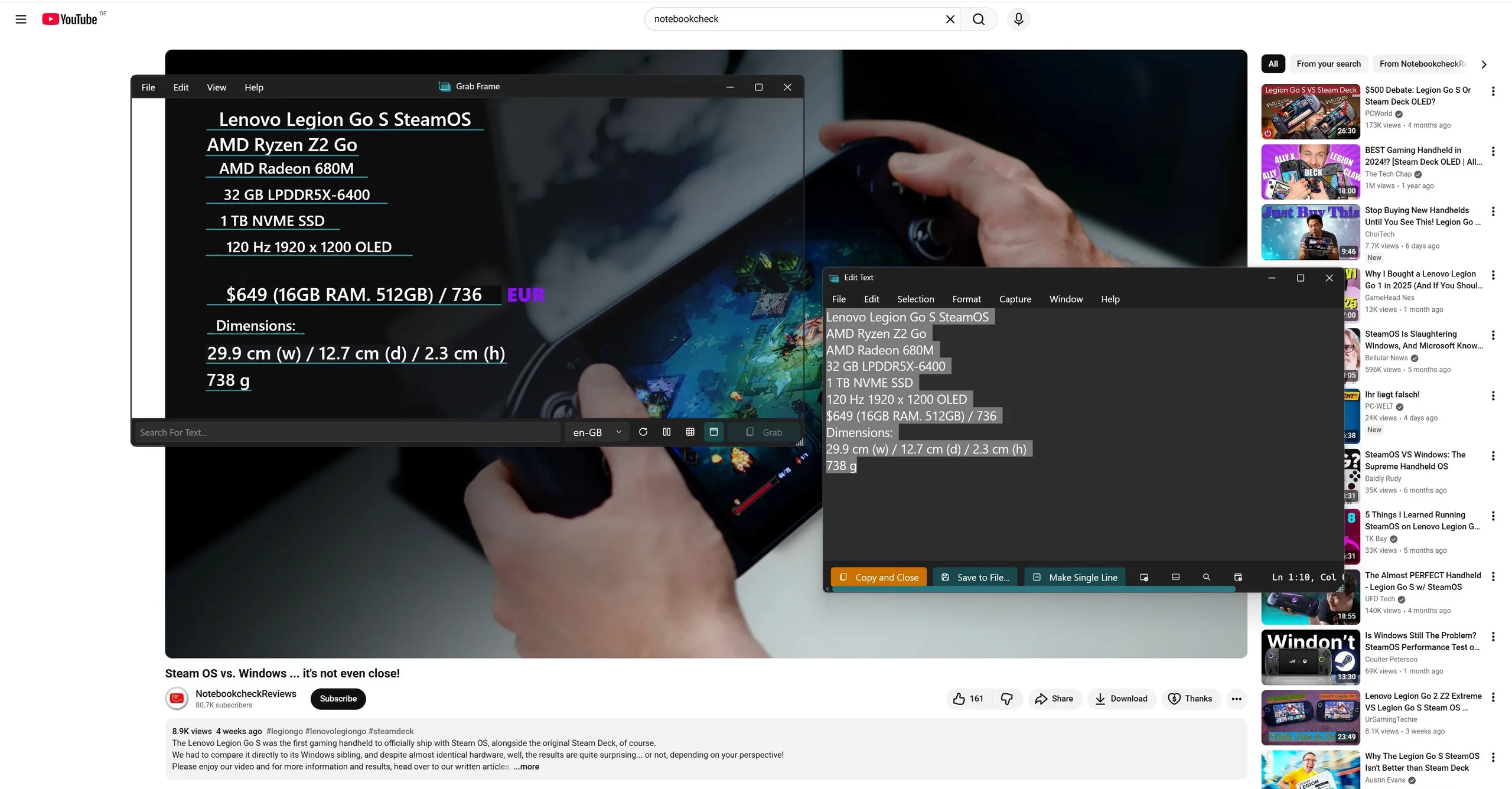
Jak to działa: Za kulisami aplikacja wykonuje zrzut ekranu i wysyła go do silnika OCR (optyczne rozpoznawanie znaków) wbudowanego w interfejs API systemu Windows. Wszystko działa lokalnie.
Narzędzie jest ogólnie bardzo dokładne, lekkie i w pełni open source. Nie jest jednak doskonałe. Zdarzyło mi się kilka przypadków, w których źle coś odczytało, ale wbudowany edytor, który wyskakuje automatycznie, ułatwia szybkie wprowadzanie poprawek.

