CheckMag | Brak GPU, żaden problem. Hostowanie własnego LLM jest nieskończenie przyjemniejsze niż cenzurowane oferty dużych graczy i działa zaskakująco dobrze.

To, co faktycznie dzieje się z Państwa danymi, gdy wysyłają Państwo zapytanie do sztucznej inteligencji, jest w zasadzie kwestią domysłów, ale cokolwiek się z nimi dzieje, z pewnością nie należą już do Państwa.
Obok generowanie obrazów i wideo, jeśli chcą Państwo poeksperymentować z dużymi modelami językowymi (LLM), ale nie chcą przekazywać swoich danych wielkim technologiom, hosting własnych jest zaskakująco łatwy i ma kilka zalet w porównaniu z dużymi graczami.
Przede wszystkim, niezależnie od tego, co zdecydują się Państwo z tym zrobić, wszystkie dane pozostają pod Państwa kontrolą, co, jeśli nie chcą Państwo przekazywać swoich danych do Mechahitlerjest natychmiastowym plusem. Mogą Państwo również korzystać z praktycznie dowolnego modelu, niezależnie od tego, czy jest to Deepseek, Gemma2 czy GPT, a dodatkową zaletą jest możliwość korzystania z wersji, które nie ograniczają typów zapytań, które można do niego wrzucić.
KoboldCPP to łatwe w użyciu, jednowykonywalne narzędzie do generowania tekstu AI, zaprojektowane do uruchamiania dużych modeli językowych GGUF i GGML. Obsługuje zarówno GPU, jak i CPU i może działać jako wyspecjalizowany backend do opowiadania historii i czatu AI. KoboldCPP można pobrać z GitHub tutaj i jest dostępny dla systemów Windows, Linux, Mac lub Docker.
Hostowanie w kontenerze sprawia, że wystawienie LLM na każde urządzenie w sieci jest banalnie proste, a istnieją gotowe szablony dla głównych platform, w tym Unraid i TrueNAS. To samo można osiągnąć w przypadku innych instalacji, o ile dodadzą Państwo niezbędne reguły do zapory sieciowej.
Pierwsze kroki
Gdy już zdecydują się Państwo na wybraną platformę, należy zastanowić się, jakiego modelu użyć. Hugging Face to najlepsze miejsce do szukania modeli, które muszą być w formacie GGUF.
Jeśli planują Państwo organizować scenariusze D&D, z pewnością będą Państwo potrzebować nieocenzurowanego modelu, w przeciwnym razie LLM ostatecznie odmówi skrzywdzenia którejkolwiek z postaci i może wygenerować niepożądane wyniki niepożądane rezultaty.
Niektóre modele, takie jak Deepseek i Claudemają skłonność do "myślenia", co w zasadzie powoduje wypluwanie całego procesu myślowego zapytania. Może to być w porządku, gdy procesor graficzny wykonuje ciężką pracę, ale bez niego znacznie spowalnia proces. Będą Państwo musieli poeksperymentować z modelami, aby znaleźć taki, który będzie dla Państwa odpowiedni, ale Gemma2 jest dobrym miejscem do rozpoczęcia.
Proszę znaleźć stronę z plikami i skopiować adres URL, który prowadzi do pliku GGUF. Wiele modeli ma różne rozmiary, więc należy wybrać taki, który pasuje do ograniczeń dostępnej pamięci RAM.
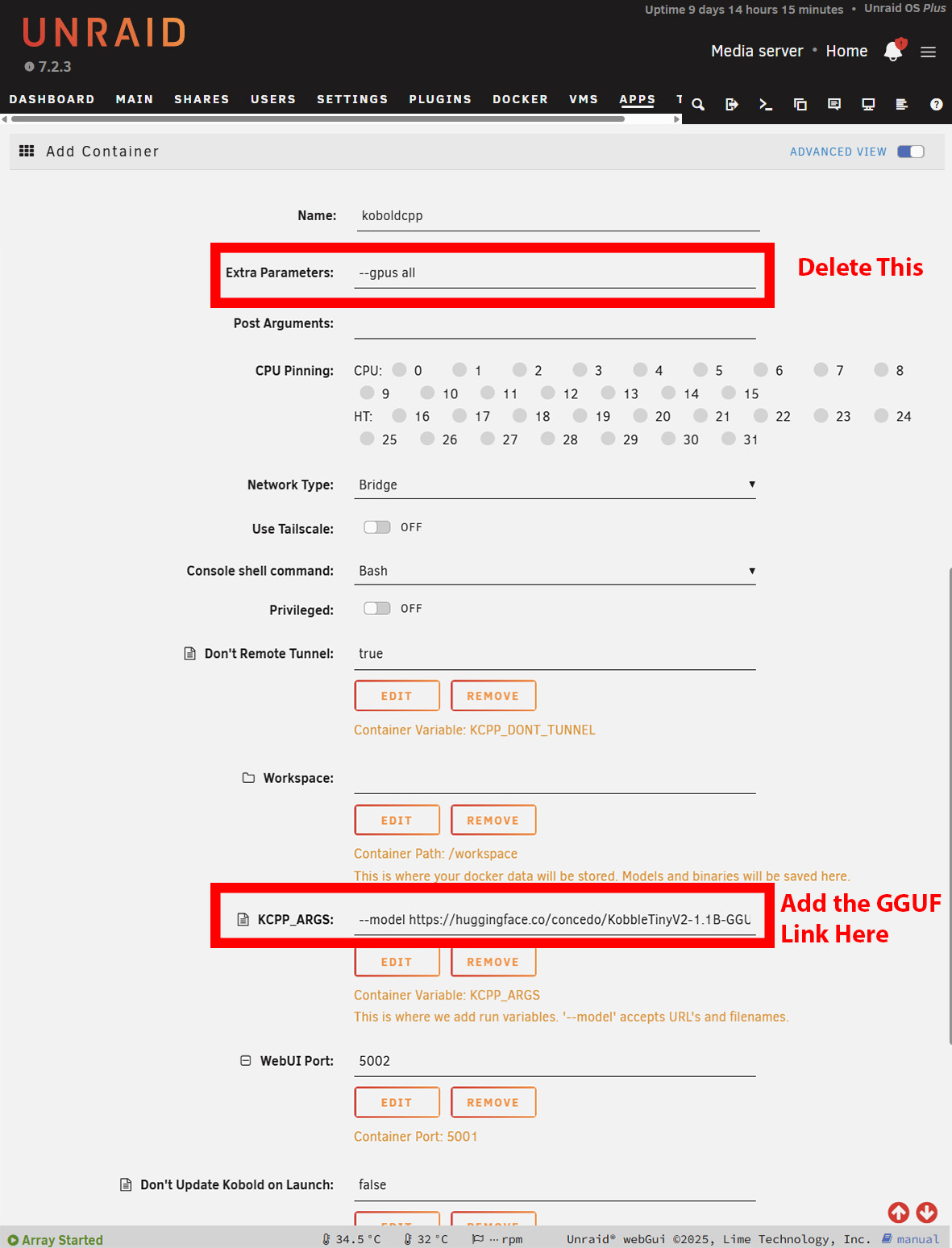
Instalacja w systemie Windows jest w dużej mierze taka sama. Należy jednak pobrać wersję NoCUDA w przypadku korzystania bez GPU. Uruchomienie może chwilę potrwać, ponieważ KoboldCPP pobierze model przed wyświetleniem interfejsu. W systemie Windows jest to oczywiste, ale w przypadku Unraid lub TrueNAS trzeba otworzyć dzienniki, aby zobaczyć postęp pobierania. W przypadku Unraid może być konieczne zwiększenie https://forums.unraid.net/topic/141244-how-do-i-increase-the-size-of-the-docker-image/ dostępnej przestrzeni dyskowej kontenerów Docker w zależności od wielkości wybranego modelu.
KoboldCPP oferuje 4 różne tryby interfejsu, w tym instruktaż, fabułę, czat i przygodę.
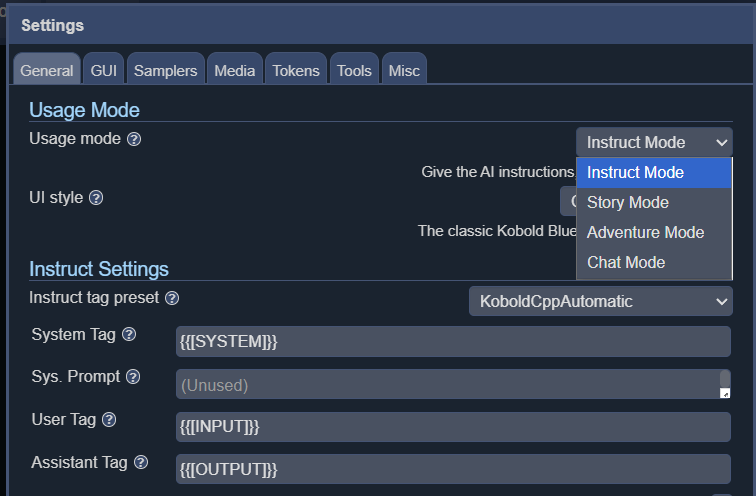
Choć nie jest najszybsza pod żadnym względem, tekst generowany jest nieco wolniej niż przeciętna prędkość czytania. Doskonale nadaje się do scenariuszy D&D, gdy działa na 16-rdzeniowym AMD 5950x(dostępnym na Amazon) i prawdopodobnie będzie działać szybciej na bardziej nowoczesnych procesorach. Im więcej rdzeni, tym lepiej, a przyzwoita ilość pamięci RAM pozwoli na uruchomienie większych modeli, choć 16 GB powinno wystarczyć. Rozmiar i typ modelu będzie miał również znaczący wpływ na szybkość generowania, a wybór lżejszego modelu może znacznie zwiększyć ogólną prędkość.
Oczywiście, aby uzyskać najlepsze wrażenia, optymalne jest uruchamianie dużych modeli językowych za pomocą GPU, jednak jeśli chcą Państwo spróbować hostować własne, omijając ograniczenia lub implikacje związane z prywatnością danych ChatGPT, Claude lub Gemini, nie potrzebują Państwo żadnego wymyślnego sprzętu, aby rozpocząć, a nadal można uzyskać przyzwoite wrażenia.
Źródło(a)

