 Deutsch
Deutsch English
English Español
Español Français
Français Italiano
Italiano Nederlands
Nederlands Polski
Polski Português
Português Русский
Русский Türkçe
Türkçe Svenska
Svenska Chinese
Chinese Magyar
MagyarTechnologia sztucznej inteligencji Uniwersytetu Waszyngtońskiego pozwala użytkownikom słuchawek wybrać konkretne dźwięki do słuchania

Zespół kierowany przez naukowców z Uniwersytetu Waszyngtońskiego (UofW) stworzył oprogramowanie AI dla słuchawek, które pozwala użytkownikom wybrać określone dźwięki do usłyszenia. W przeciwieństwie do słuchawek z redukcją szumów, które po prostu odfiltrowują wszystko oprócz głosów, nowa sieć neuronowa pozwala użytkownikom wybrać określone dźwięki, takie jak ćwierkanie ptaka.
Wcześniejsze słuchawki, takie jak Sony INZONE(dostępne na Amazon) wykorzystują DSEE Extreme, Speak-to-Chati AI DNNaI w celu poprawy jakości muzyki i mowy, jednocześnie automatycznie pozwalając głosom na redukcję szumów po rozpoczęciu rozmowy. Praca UofW rozwija się w tym kierunku, umożliwiając słuchaczom wybór spośród 20 różnych rodzajów dźwięków, takich jak ćwierkanie ptaków, ocean, pukanie do drzwi i spłukiwanie toalety, jednocześnie odfiltrowując wszystkie inne. Nazywa się to słyszeniem semantycznym, co pozwala użytkownikom cieszyć się ćwierkaniem ptaków w parku bez słyszenia rozmów ludzi lub przejeżdżających samochodów.
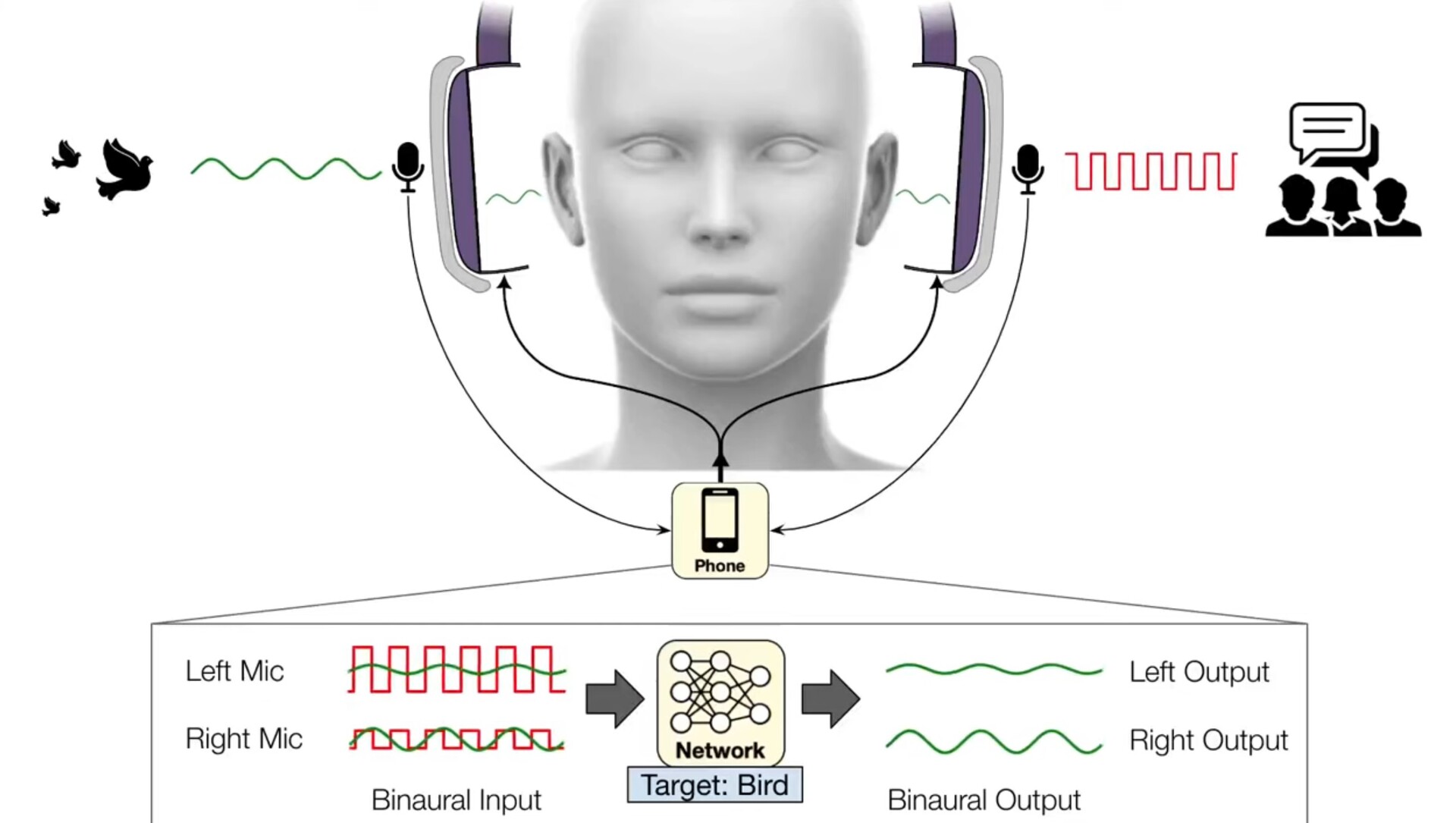
Obecnie aplikacja UofW wykorzystuje mikrofony obuuszne do przechwytywania pozycji dźwięków zewnętrznych w czasie rzeczywistym przed wysłaniem przefiltrowanych dźwięków do słuchawek. Ponieważ oprogramowanie działa na smartfonach, ich aplikacja może wykorzystywać mocniejsze procesory niż te znajdujące się w słuchawkach, jednak to tylko kwestia czasu, zanim słuchawki z redukcją szumów będą miały wbudowane słyszenie semantyczne.


Źródło(a)
University of Washington, ACMoraz Paul G. Allen School (YouTube)
9 listopada 2023 r
Nowa technologia słuchawek z redukcją szumów AI pozwala użytkownikom wybrać, które dźwięki słyszą
Stefan Milne
UW News
Większość osób korzystających ze słuchawek z redukcją szumów wie, że słyszenie odpowiedniego hałasu we właściwym czasie może mieć kluczowe znaczenie. Ktoś może chcieć usunąć klaksony samochodów podczas pracy w pomieszczeniu, ale nie podczas spaceru po ruchliwych ulicach. Jednak ludzie nie mogą wybrać, jakie dźwięki ich słuchawki anulują.
Teraz zespół kierowany przez naukowców z University of Washington opracował algorytmy głębokiego uczenia, które pozwalają użytkownikom wybrać, które dźwięki filtrują przez ich słuchawki w czasie rzeczywistym. Zespół nazywa ten system "semantycznym słyszeniem" Słuchawki przesyłają przechwycony dźwięk do podłączonego smartfona, który eliminuje wszystkie dźwięki otoczenia. Za pomocą poleceń głosowych lub aplikacji na smartfona, użytkownicy słuchawek mogą wybrać, które dźwięki chcą uwzględnić spośród 20 klas, takich jak syreny, płacz dziecka, mowa, odkurzacze i ćwierkanie ptaków. Tylko wybrane dźwięki będą odtwarzane przez słuchawki.
Zespół zaprezentował swoje odkrycia 1 listopada na UIST '23 w San Francisco. W przyszłości naukowcy planują wypuścić komercyjną wersję systemu.
"Zrozumienie, jak brzmi ptak i wyodrębnienie go ze wszystkich innych dźwięków w środowisku wymaga inteligencji w czasie rzeczywistym, której dzisiejsze słuchawki z redukcją szumów nie osiągnęły" - powiedział starszy autor Shyam Gollakota, profesor UW w Paul G. Allen School of Computer Science & Engineering. "Wyzwanie polega na tym, że dźwięki słyszane przez użytkowników słuchawek muszą być zsynchronizowane z ich zmysłami wzroku. Nie można słyszeć czyjegoś głosu dwie sekundy po tym, jak ktoś do nas mówi. Oznacza to, że algorytmy neuronowe muszą przetwarzać dźwięki w czasie poniżej jednej setnej sekundy"
Z tego powodu system semantycznego słyszenia musi przetwarzać dźwięki na urządzeniu takim jak podłączony smartfon, zamiast na bardziej niezawodnych serwerach w chmurze. Dodatkowo, ponieważ dźwięki z różnych kierunków docierają do uszu ludzi w różnym czasie, system musi zachować te opóźnienia i inne wskazówki przestrzenne, aby ludzie mogli nadal sensownie odbierać dźwięki w swoim otoczeniu.
Testowany w środowiskach takich jak biura, ulice i parki, system był w stanie wyodrębnić syreny, ćwierkanie ptaków, alarmy i inne dźwięki docelowe, jednocześnie usuwając wszelkie inne hałasy ze świata rzeczywistego. Kiedy 22 uczestników oceniło wyjście audio systemu dla dźwięku docelowego, stwierdzili, że średnio jakość poprawiła się w porównaniu z oryginalnym nagraniem. W niektórych przypadkach system miał trudności z rozróżnieniem dźwięków, które mają wiele wspólnych właściwości, takich jak muzyka wokalna i ludzka mowa. Naukowcy zauważają, że szkolenie modeli na większej ilości rzeczywistych danych może poprawić te wyniki.
Dodatkowymi współautorami artykułu byli Bandhav Veluri i Malek Itani, obaj doktoranci UW w Allen School; Justin Chan, który ukończył te badania jako doktorant w Allen School i obecnie pracuje na Carnegie Mellon University; oraz Takuya Yoshioka, dyrektor ds. badań w AssemblyAI.
Aby uzyskać więcej informacji, proszę skontaktować się z [email protected].








